Follow by Sandro Luck (Data With Sandro)
As we are starting the year 2021, we have to talk about something that has been brought up a lot lately. As more and more people spend their time at home, creating, listening, and using music in various projects becomes a more central part of many lives. The first successes in music generation, production, and editing done by Artificial Intelligence-driven software are staggering and will accelerate this trend further.
Now I don’t want to say that AI will completely automate the music industry in 2021, but creating professional quality music is definitely becoming easier and cheaper in the near future.
Automatic Music Generation using AI
Automatically creating music is particularly hard for many reasons. The most hampering being that a simple 3-minute song a band of humans can easily memorize has just way too many variables for a computer.
Additionally, the ideal way to train an AI (aka loss function) to become a Musician is unknown. The goal itself for us developers is also far from obvious. Are we trying to generate music from thin air or based on some form of input? Or are we trying to generate a system that can accompany a human musician while playing?
While I believe currently, for musicians, there is no reason to panic about their job prospects. We will look at three companies trying to automatically generate music and see if possibly soon the first Grammy will be given to a Data Scientist.
OpenAI’s Jukebox — For Futurists
OpenAI is one of those company that has been founded by that deer loving, rocket building car mechanic called Elon Musk. They have several artistic projects, most notably GPT-3 for literature, but Jukebox has a special space in my heart as a music lover.
We’re introducing Jukebox, a neural net that generates music, including rudimentary singing, as raw audio in a variety of genres and artist styles — OpenAI
The basic idea is that they take raw audio and encode it using Convolutional Neural Networks(CNNs). Think of it as a way to compress many variables into fewer variables. They have to do this since audio has 44’100 variables per second and a song has many seconds. They then do their generation process on this smaller variable set and decompress back to the 44’100 variables.
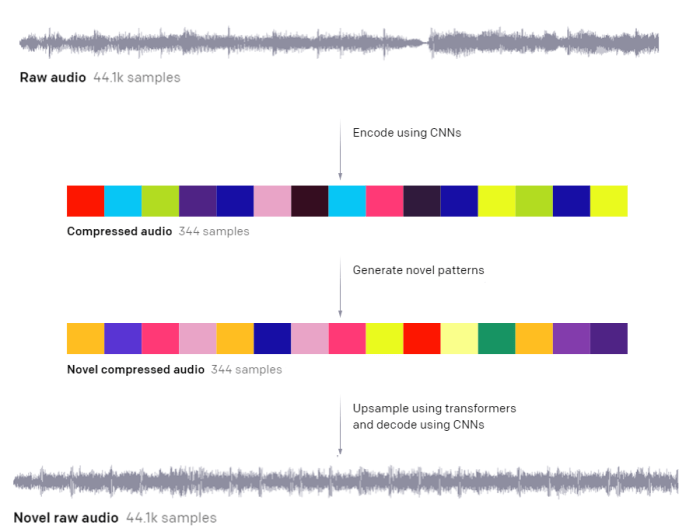
Example Pop, in the style of Rick Astley — Jukebox
This example has been generated by giving the AI 10 seconds of the song and generating the rest.
WARNING: Listen for at least 10 seconds only after this the generated part starts
While this song still has a lot of noise in it, it clearly is a step in the right direction.
Future Direction OpenAI, more promising?
Their more recent discoveries come from generating their music by conditioning on a MIDI-file, which you can imagine to be like a music sheet giving rough instructions to the musicians (we are going to explain the details in the end).
I feel this approach will have far more (near-term) success. The goal is basically, given a sheet of music, generate the MP3 recording for me.
AIVA — For Creators
AIVA is much like OpenAI’s Jukebox, an approach to generate music. However, their approaches diverge in the underlying data structure they generate it from. AIVA operates on the so-called MIDI file. Keep imagining the MIDI file to be like a music sheet. The difference here is that OpenAI in the last example took the MIDI file and generated an Audio recording. But AIVA creates, given a MIDI file, a similar yet completely new and different piece of composition.
Their approach is that we can upload a song in the MIDI format. They will use this song to condition their generation process. In other words, this song will influence the generated song.
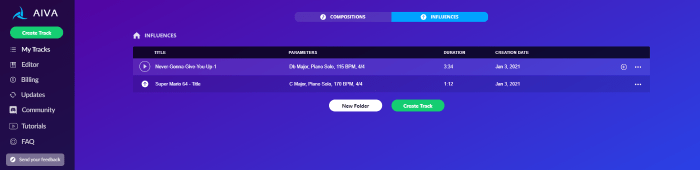
I tried this with two songs, “Never Gonna Give you up,” and the other being “Super Mario Theme.” After choosing one song to condition on, we are given some options. As of now, we can sadly only condition on one song.

I chose to generate 3 compositions for each influence with a short length of <0:30 seconds. I found that it worked very well on the simple “Super Mario Theme” song and rather bad for the “Never Gonna Give you up” song.
It seems to ignore the more complex song “Never Gonna Give you up,” I assume this is due to the relative complexity. Judge the results of the “Super Mario Theme” yourself.
While I generally feel that this tool can be a great starting point for new compositions and composers, heavy human assistance is still necessary to generate a proper song at this stage.
Amper Music — For Everyone
A completely different approach takes Amper Music. Instead of allowing us to control the generation process, Amper well generates the music. It does so by using so-called Descriptors.
Descriptors are musical algorithms that play a specific style of music. One descriptor might be born to play punky New York rock, and another might excel at chilled out beachside folk — Amper Music
We can at generation time choose two things. One is the length of the song. And the other is a set of (given) adjectives describing the Descriptor verbally. For example, I chose a “Playful Futuristic, Documentary,” and the result is quite lovely and potentially usable. After this, you are also prompted to select a set of instruments to be chosen as a basis. I went with Forks and Knives.
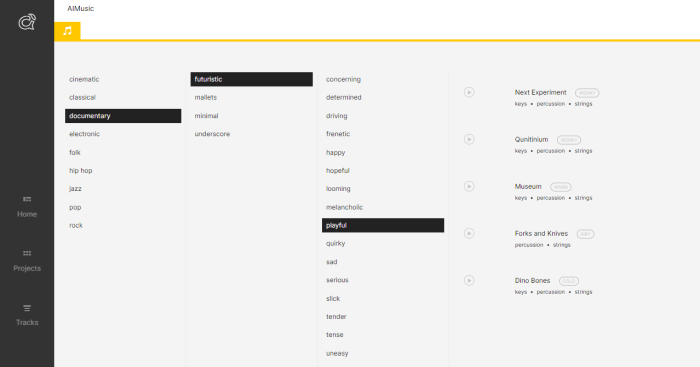
The result is excellent, and I could see it being a great tune for a documentary about dog toys. When repeating the same selection of parameters, the songs may be quite repetitive but by design.
Piano Roll — How the Approaches are different
While Ampers solution is probably a mix of the other two solutions, it is hard for me to argue how exactly it works. The difference between AIVA and Jukebox is mostly of a data structure (the way the music is stored) nature. To understand the difference between Jukebox and AIVA’s, we first understand the difference between an audio recording and the MIDI standard. A MIDI can, in our case, be understood to be a collection of several Piano Rolls. Where a Piano Roll is basically one Instrument.
The Piano Roll is arguably one of the oldest specialized data structures. The basis of the Piano Roll was created in 1896. Originally designed to make pianos play automatically, they nowadays serve as a canvas for music.
On the X-axis, we have the time, and on the y-axis, the pitches in which the piano is currently playing (may include several simultaneously played pitches).

As you might imagine, this approach results in far fewer variables than a complete Audio Wave. For the Piano Roll, we have
Amount of pitches * Amount Of Voices * Amount of Quantization steps
Which for a 1-minute piece with 4 voices and 64 pitches (which is a common choice for Machine Learning). Would result in roughly
(400)*4*64 = 102'400 possibilities
Assuming: 1/16 quantization 100 beats per minute all voices are mono, simplified calculation
In contrast, a digitalized audio wave 44’100 Sample Rate will for 60 seconds result in
(44'100*60)*16 = 42'336'000 possibilites
Assuming: 44’100 Sample Rate, and 16bit Word Length and the Sound being Mono
This simplified calculation should illustrate that working on the audio wave directly is far more challenging without going too much into detail. Indeed, additional factors make working on the Audio wave more unforgiving, which was also present as the “noise” part in the Jukebox example. Such noise could not exist when generating in the MIDI format.
The main advantage of working on the wave directly is that the AI model can also create sounds that are not specific to music, such as human speech. Theoretically, they could achieve the level of a human singer’s recording by using the audio wave as a basis.
Conclusion
We have seen that computers can indeed create music that could pass a simplified turning test. The 3 solutions presented all have their place in the AI music ecosystem. AIVA is aimed at musicians that want to create with and get inspired by AI. Amper is a solution for video creators and advertisement specialists that seek to find simple yet usable audio to use in their creations.
OpenAI’s Jukebox is a research project to change how music is created and listened to entirely. While its potential is great, it remains to be seen how far they can push the boundaries between AI and music.
